|
|
|||||
|
|
|||||
|
|
|||||
|
|
|||||
|
|
Architettura ed Evoluzione del World Wide Web | ||||||||||||||||||
|
|
L’architettura base
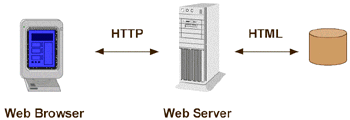
Il Web è un servizio che prevede che l’applicazione utilizzata degli utenti richieda al server il trasferimento di informazioni in esso memorizzate. Il servizio si basa essenzialmente sul trasferimento di file contenenti informazioni ipertestuali da una macchina dotata di un software in grado di ricevere ed evadere le richieste (il server) verso la macchina dell'utente (il client). Il programma eseguito sulla macchina dell’utente è detto browser e ha il compito di richiedere e visualizzare le informazioni: esempi di browser sono Netscape Navigator o Microsoft Internet Explorer. Sulla macchina server, invece, è in esecuzione un programma in grado di interpretare e soddisfare le richieste ricevute. La connessione tra client e server viene mantenuta attiva solo per il periodo nel quale viene trasferita una singola informazione (file di testo, immagine, …). Affinché un’applicazione di questo tipo possa funzionare, è necessario definire [LEE]:
Rifacendoci all’architettura generale di un sistema ipertestuale, il database è costituito dalla rete Internet e dai server Web ad essa interconnessi, il browser si occupa della parte di presentazione, mentre l’Hypertext Abstract Machine è basata su HTTP e HTML.
Figura 28: architettura client/server del Web Uniform Resource Locator (URL): l'indirizzamento L’indirizzo di una informazione su Web ha un suo formato specifico, detto URL: Uniform Resource Locator. Questo indirizzo si compone di tre parti, secondo il seguente formato: protocollo://server/informazione dove:
Un esempio di URL potrebbe, quindi, essere: http://www.ssgrr.it/it/benvenuto.htmPer poter connettersi ad un server, il browser richiede obbligatoriamente solo l’indirizzo del server. Raggiunta la pagina iniziale del server (home page), le altre informazioni in esso contenuto possono essere ottenute utilizzando i link presenti nelle pagine per la successiva navigazione. Un indirizzo DNS è abbastanza intuitivo ed ha il formato: macchina.organizzazione.tipodove:
Si può, quindi, iniziare a navigare sul Web sapendo (o indovinando) il nome del server e seguendo poi i link presenti nelle pagine in esso pubblicate. Data la grande mole di informazioni attualmente disponibile sulla rete, però, la navigazione su Internet risulta attualmente relativamente complessa. Se non si ha idea dove possano essere memorizzate le informazioni, è necessario ricorrere a strumenti che assistano nel reperimento delle pagine d'interesse. Un primo strumento è di solito messo a disposizione dai fornitori di accesso (es.: TIN), tramite delle pagine che raggruppano per tipo (es.: quotidiano, medicina, …) i siti maggiormente visitati. Lo strumento più utile, però, per trovare informazioni su Internet è dato dai motori di ricerca (es.: Yahoo, Lycos, Infoseek, Virgilio, …). Questi motori di ricerca non sono altro che dei database che contengono (su segnalazione dei gestori dei siti o tramite analisi periodiche dei siti stessi), informazioni sul contenuto delle pagine pubblicate. Questi database possono essere interrogati tramite parole chiave, ottenendo come risultato una lista di indirizzi relative a pagine che contengono gli argomenti indicati. |